Hello folks,
I am still around, I've just been taking a long vacation. I have some more articles waiting to be written, I have just been lazy during my time off. In the mean time, I want to wish everyone a Happy New Year.
Saturday, December 31, 2005
Wednesday, December 21, 2005
fork()
Several months ago, I got very interested in Linux processes, socket programming, and IPC. While I was very familiar with the concepts themselves, I had never actually written programs that utilized them. In this article, I will look at the simpler of the topics, using the Linux fork() function to generate a new process.
fork() is surprisingly easy to use. Simply make a call to fork, and you have a new process. The return from fork() is the process ID of the child ID. In the child process, the returned value is 0. This makes storing the returned value from fork necessary to determine while process is active. For example, if I have this function call:
pid = fork();
pid in the parent process will be assigned the value of the child process ID, and inside the child process, pid will be assigned 0. I really thought there would be more to it, but in a nutshell, that is basically it. Below is an example program. The program will fork a process. The parent will count to 100 by 2, starting at 0, and the child will count to 101 starting at 1. Both will display to the same console, so the output will need to identify itself as the child or parent process. The example was compiled with GCC under Cygwin with no problems.
//Two C headers needed for the process ID type and the system calls to fork processes
#include <sys/types.h>
#include <unistd.h>
//I prefer the C++ style IO over the C style
#include <iostream>
//Needed to call IOSTREAM in the standard namespace without prefix
using namespace std;
int main()
{
//variable to store the forked process ID
pid_t process_id;
//counter to be used in the loops
int counter;
//Fork the process ID, and if there is an error, exit the program with an error
process_id = fork();
if (process_id < 0)
{
cerr << "Process failed to create!" << endl;
exit(1);
}
//If the process ID is not 0, it is the parent process. The parent process will counter from 0 to 100 and increment
//by two each time. The child process will have a process_id of 0, and increment by 2 starting from 1.
if (process_id)
{
//Let the user know what the parent ID is and the generated child ID
cout << "I am the parent ID. My PID is: " << getpid() << " and my Childs process ID is " << process_id << endl;
for (counter = 0; counter <= 100; counter += 2)
{
cout << "Parent (" << getpid() << "): " << counter << endl;
}
}
else
{
//Tell the user what the current process ID is using getpid to verify it is the child process, then show
//that process_id is 0
cout << "I am the Child ID " << getpid() << " and I think the assigned process ID is " << process_id << endl;
for (counter = 1; counter <= 101; counter += 2)
{
cout << "Child(" << getpid() << "): " << counter << endl;
}
}
return 0;
}
Being able to spawn separate processes is incredible useful in handling multiple connection in a server program. Sharing variables between multiple processes gets really interesting. This is where the various IPC methods come in to play, but that’s for another article.
fork() is surprisingly easy to use. Simply make a call to fork, and you have a new process. The return from fork() is the process ID of the child ID. In the child process, the returned value is 0. This makes storing the returned value from fork necessary to determine while process is active. For example, if I have this function call:
pid = fork();
pid in the parent process will be assigned the value of the child process ID, and inside the child process, pid will be assigned 0. I really thought there would be more to it, but in a nutshell, that is basically it. Below is an example program. The program will fork a process. The parent will count to 100 by 2, starting at 0, and the child will count to 101 starting at 1. Both will display to the same console, so the output will need to identify itself as the child or parent process. The example was compiled with GCC under Cygwin with no problems.
//Two C headers needed for the process ID type and the system calls to fork processes
#include <sys/types.h>
#include <unistd.h>
//I prefer the C++ style IO over the C style
#include <iostream>
//Needed to call IOSTREAM in the standard namespace without prefix
using namespace std;
int main()
{
//variable to store the forked process ID
pid_t process_id;
//counter to be used in the loops
int counter;
//Fork the process ID, and if there is an error, exit the program with an error
process_id = fork();
if (process_id < 0)
{
cerr << "Process failed to create!" << endl;
exit(1);
}
//If the process ID is not 0, it is the parent process. The parent process will counter from 0 to 100 and increment
//by two each time. The child process will have a process_id of 0, and increment by 2 starting from 1.
if (process_id)
{
//Let the user know what the parent ID is and the generated child ID
cout << "I am the parent ID. My PID is: " << getpid() << " and my Childs process ID is " << process_id << endl;
for (counter = 0; counter <= 100; counter += 2)
{
cout << "Parent (" << getpid() << "): " << counter << endl;
}
}
else
{
//Tell the user what the current process ID is using getpid to verify it is the child process, then show
//that process_id is 0
cout << "I am the Child ID " << getpid() << " and I think the assigned process ID is " << process_id << endl;
for (counter = 1; counter <= 101; counter += 2)
{
cout << "Child(" << getpid() << "): " << counter << endl;
}
}
return 0;
}
Being able to spawn separate processes is incredible useful in handling multiple connection in a server program. Sharing variables between multiple processes gets really interesting. This is where the various IPC methods come in to play, but that’s for another article.
Tuesday, December 20, 2005
Classic Physics produces similar Cryptography to Quantum, or so they say..
Thanks to Linuxsecurity.com for their post about this Wired article. Quantum-like cryptography for half the price using run of the mill physics seems like a really cool concept, even if the concept is a little over my head. Using the noise present in resistors seems sound in theory, but even resistors at the same Ohm value slightly differ, causing the noise generated on each side to slightly differ (very minute amount) so I am assuming there is a slight margin for error. Based on the papers, it doesn’t look like they have a practical application of this yet, but it’s a pretty cool-sounding idea if it actually works. Maybe someone a little more knowledgeable in physics can explain this…
Monday, December 19, 2005
My thoughts on Monoculture
As an avid reader of both of Tom Ptacek and Richard Bejtlichs blogs, I think these two may need to be separated to avoid further disruption of the rest of the class. These guys never agree on anything, kind of like the Siskel and Ebert of computer security (or is that Roper now…) All kidding aside, both sides of the argument are correct and have their merits, and at the same time, neither are the final, correct answer. Let me explain my view on this.
First, let me give you the Cliffs Notes version of this debate. It is a widely known fact that the monopoly held by Microsoft Windows on the desktop market is a security nightmare due to the number of vulnerabilities, speed of disclosure and time to market for security updates. This brought up the debate about a single platform everyone uses being a security weakness both for individuals and for national security. This lack of diversity in the market is being labeled as a “Monoculture” (although I think I am going to use this term to refer to the skanky one-night stands at bars, it seems more appropriate). In Dan Geers article “Monoculture on the Back of the Envelope”, he is arguing for diversity of platforms, which I will label as a “Polyculture”, for the IT industry.
The “Monoculture” has several advantages, which is what makes it so popular. First, is standardization. Ideally, all systems in the environment are running on the same platform and have the same software. It is very easy to administer a network with a standard desktop image and similar software. Time to rollout administrative policies, software updates, and security fixes are minimized in this type of environment. The downside to this is if there is an exploit for vulnerability on this platform, the intruder basically has the keys to the kingdom.
The “Polyculture” on the other hand, limits this. In a “Polyculture”, a vulnerability on one single platform can be contained and only affects the vulnerable systems. However, as Halvar Flake points out (which I would normally discount as invalid due to the arrogance of his tone, but I will ignore and count as a valid point anyway) if there is a valuable piece of information, such as the source to Company A software package, distributed on different platforms, an intruder only needs to exploit one vulnerable platform to have access to that valuable piece of information. So if the goal of the intruder is to get that valuable piece of information, this paradigm is severely flawed. Also, once one system is owned, it is only a matter of time before a skilled intruder can research and exploit the diverse platforms, making the intruder not only a bigger threat to the compromised organization, but other organizations as well.
So here are my thoughts on this. I believe there is very little evidence to credit a “Monoculture” as a major security weakness or strength for all scenarios. In some scenarios, such as Halvar’s example, it can be a potential strength. In other examples, such as with worms, it is a major detriment. I believe a “Polyculture” is a natural evolution from a “Monoculture”, and is more than likely a Windows shop diversifying into a Windows/Linux/MacOS shop. Therefore, chances are that the weakest link in the chain more than likely is a vulnerability in the software that exists in the “Monoculture” as well as the “Polyculture” since that vulnerable system will exist in both environments. The whole “Monoculture” argument is smoke and mirrors, another example of security through obscurity by diversifying the environment, another example of the argument of sacrificing usability vs. security, and a chance for someone to write a “paper” to get a new buzzword out there for us to all argue about. Both sides have their pros and their cons, leading to the conclusion that once again, security researchers have created a ruckus and have failed to find that security “silver bullet”, distracting us from the real issues of piss-poor security policies, piss-poor management, and failure to communicate risk effectively to management. The concept of diversifying the environment is just another tool in the security toolkit, and may not be appropriate for all scenarios. A well-managed Windows only network will be just as secure as a hybrid network consisting of multiple platforms; the only difference is the increased difficulty in management.
My final thoughts on this, this seems to me like a thinly veiled argument to “ditch Windows in favor of authors favorite platform X, but start slow and only do a few systems at a time”. If you don’t like Windows, don’t use it, but don’t make up these ridiculous arguments about IT cultural diversity and complain about how only 30 percent of the laptops you see at conferences are Macs, just call it what it is.
Update (12-20-2005): Thomas Ptacek updated his post and just about hit the nail on the head as far as I am concerned. “But the problem with the monoculture argument is that it simply isn't real” is absolutly, 100 percent, right on the money. The monoculture argument is an argument that is best left out of the security equation and left more to the management to decide the best path to productivity (example: Mac for the graphic artists, PC’s for the programmers, *nix for the servers, etc). And kudos for going one step further and pointing out that there are other “Monocultures” out there.
First, let me give you the Cliffs Notes version of this debate. It is a widely known fact that the monopoly held by Microsoft Windows on the desktop market is a security nightmare due to the number of vulnerabilities, speed of disclosure and time to market for security updates. This brought up the debate about a single platform everyone uses being a security weakness both for individuals and for national security. This lack of diversity in the market is being labeled as a “Monoculture” (although I think I am going to use this term to refer to the skanky one-night stands at bars, it seems more appropriate). In Dan Geers article “Monoculture on the Back of the Envelope”, he is arguing for diversity of platforms, which I will label as a “Polyculture”, for the IT industry.
The “Monoculture” has several advantages, which is what makes it so popular. First, is standardization. Ideally, all systems in the environment are running on the same platform and have the same software. It is very easy to administer a network with a standard desktop image and similar software. Time to rollout administrative policies, software updates, and security fixes are minimized in this type of environment. The downside to this is if there is an exploit for vulnerability on this platform, the intruder basically has the keys to the kingdom.
The “Polyculture” on the other hand, limits this. In a “Polyculture”, a vulnerability on one single platform can be contained and only affects the vulnerable systems. However, as Halvar Flake points out (which I would normally discount as invalid due to the arrogance of his tone, but I will ignore and count as a valid point anyway) if there is a valuable piece of information, such as the source to Company A software package, distributed on different platforms, an intruder only needs to exploit one vulnerable platform to have access to that valuable piece of information. So if the goal of the intruder is to get that valuable piece of information, this paradigm is severely flawed. Also, once one system is owned, it is only a matter of time before a skilled intruder can research and exploit the diverse platforms, making the intruder not only a bigger threat to the compromised organization, but other organizations as well.
So here are my thoughts on this. I believe there is very little evidence to credit a “Monoculture” as a major security weakness or strength for all scenarios. In some scenarios, such as Halvar’s example, it can be a potential strength. In other examples, such as with worms, it is a major detriment. I believe a “Polyculture” is a natural evolution from a “Monoculture”, and is more than likely a Windows shop diversifying into a Windows/Linux/MacOS shop. Therefore, chances are that the weakest link in the chain more than likely is a vulnerability in the software that exists in the “Monoculture” as well as the “Polyculture” since that vulnerable system will exist in both environments. The whole “Monoculture” argument is smoke and mirrors, another example of security through obscurity by diversifying the environment, another example of the argument of sacrificing usability vs. security, and a chance for someone to write a “paper” to get a new buzzword out there for us to all argue about. Both sides have their pros and their cons, leading to the conclusion that once again, security researchers have created a ruckus and have failed to find that security “silver bullet”, distracting us from the real issues of piss-poor security policies, piss-poor management, and failure to communicate risk effectively to management. The concept of diversifying the environment is just another tool in the security toolkit, and may not be appropriate for all scenarios. A well-managed Windows only network will be just as secure as a hybrid network consisting of multiple platforms; the only difference is the increased difficulty in management.
My final thoughts on this, this seems to me like a thinly veiled argument to “ditch Windows in favor of authors favorite platform X, but start slow and only do a few systems at a time”. If you don’t like Windows, don’t use it, but don’t make up these ridiculous arguments about IT cultural diversity and complain about how only 30 percent of the laptops you see at conferences are Macs, just call it what it is.
Update (12-20-2005): Thomas Ptacek updated his post and just about hit the nail on the head as far as I am concerned. “But the problem with the monoculture argument is that it simply isn't real” is absolutly, 100 percent, right on the money. The monoculture argument is an argument that is best left out of the security equation and left more to the management to decide the best path to productivity (example: Mac for the graphic artists, PC’s for the programmers, *nix for the servers, etc). And kudos for going one step further and pointing out that there are other “Monocultures” out there.
Friday, December 16, 2005
Export Oracle Delimeted Text Files
A question that has come up a few times recently is how to output Oracle data to delimited text file for a file transfer. There are a number of third party tools that do this sort of thing, and Oracle does not offer a tool directly for doing this, however SQL*Plus can be used for this purpose quite effectively. The Command Line version of SQL*Plus is the best option for this since it can easily be scripted in my opinion.
My preferred method is to create a text file with the commands to generate the feed, and pipe them in to SQL*Plus, redirecting the output to the file to be transferred. For example, lets say we need to generate a feed with 3 simple fields, an Employee ID, a date stamp, and a category identifier. The file I will create will look like this:
set linesize 120;
set feedback off;
set HEADING off; --optional flag set, explained below
set pagesize 0;
SELECT
EMPID || '|' || to_char(datestamp, ‘dd-mmm-yyyy’) || '|' || category
FROM
MY_TABLE;
/
The field delimiter in the above example is set to the pipe character. This can easily be changed by editing the query. I typically use pipe since it is not commonly used in the data fields that I normally work with. This script can be run from either a DOS prompt or from within a batch file using the following command:
type above_file.sql | sqlplus -s user/password@database_name > output_file.txt
Some people will suggest spooling the output file rather than redirecting, however I prefer redirecting from the standard output due to the flexibility offered by using command line tools, such as those supplied by Cygwin (my preference for a GNU port to Windows). For example, lets say “set pagesize 0”, which will remove the column headings, was omitted from the above script. While “Set heading off” will remove the wording, an extra blank line will be included in the feed. If I wanted to eliminate the additional blank lines where the column heading would be, I could pipe the results into the “strings” command to remove the blank lines. I actually receive feeds like this, so it is a useful tip to keep in mind when processing feeds as well as generating them. Another example is if I wanted to do a cheap and dirty sort by piping into the “sort” command. This is especially useful if you are on a restricted system with no access to the original SQL file to modify the query itself to add an “order by” clause.
I highly recommend installing Cygwin to supplement Windows to help with your automated feed process if a dedicated *nix system is not available. The tools offered by Cygwin are very robust and flexible for scripting. For example the Unix date command is much more powerful than its DOS/Windows counterpart. If I want to append the run date to the end of the feed file name, it is a trivial task. Below is an example for a DOS batch file using the above script:
c:\cygwin\bin\bash -c "/usr/bin/cat /cygdrive/c/auto_rpt/etc/above_file.sql | sqlplus -s user/password@database_name > /cygdrive/c/auto_rpt/feed_archive/above_file/`/usr/bin/date +%%F`_ output_file.txt"
(Note: In the above command, the two percent signs are necessary inside of a DOS Batch file. On a regular command prompt, eliminate one of the percent signs. I always use full paths inside of automated scripts to operate under the assumption that the same PATH statements differ between my automated scripts account and my general user accounts. Not including the full paths has been the source of a number of headaches for several developers I have worked with in the past, so I try not to fall into the same pitfall whenever possible. There are a few other tips for using Cygwin in scripting feeds and file transfers, but I will save them for another article.)
My preferred method is to create a text file with the commands to generate the feed, and pipe them in to SQL*Plus, redirecting the output to the file to be transferred. For example, lets say we need to generate a feed with 3 simple fields, an Employee ID, a date stamp, and a category identifier. The file I will create will look like this:
set linesize 120;
set feedback off;
set HEADING off; --optional flag set, explained below
set pagesize 0;
SELECT
EMPID || '|' || to_char(datestamp, ‘dd-mmm-yyyy’) || '|' || category
FROM
MY_TABLE;
/
The field delimiter in the above example is set to the pipe character. This can easily be changed by editing the query. I typically use pipe since it is not commonly used in the data fields that I normally work with. This script can be run from either a DOS prompt or from within a batch file using the following command:
type above_file.sql | sqlplus -s user/password@database_name > output_file.txt
Some people will suggest spooling the output file rather than redirecting, however I prefer redirecting from the standard output due to the flexibility offered by using command line tools, such as those supplied by Cygwin (my preference for a GNU port to Windows). For example, lets say “set pagesize 0”, which will remove the column headings, was omitted from the above script. While “Set heading off” will remove the wording, an extra blank line will be included in the feed. If I wanted to eliminate the additional blank lines where the column heading would be, I could pipe the results into the “strings” command to remove the blank lines. I actually receive feeds like this, so it is a useful tip to keep in mind when processing feeds as well as generating them. Another example is if I wanted to do a cheap and dirty sort by piping into the “sort” command. This is especially useful if you are on a restricted system with no access to the original SQL file to modify the query itself to add an “order by” clause.
I highly recommend installing Cygwin to supplement Windows to help with your automated feed process if a dedicated *nix system is not available. The tools offered by Cygwin are very robust and flexible for scripting. For example the Unix date command is much more powerful than its DOS/Windows counterpart. If I want to append the run date to the end of the feed file name, it is a trivial task. Below is an example for a DOS batch file using the above script:
c:\cygwin\bin\bash -c "/usr/bin/cat /cygdrive/c/auto_rpt/etc/above_file.sql | sqlplus -s user/password@database_name > /cygdrive/c/auto_rpt/feed_archive/above_file/`/usr/bin/date +%%F`_ output_file.txt"
(Note: In the above command, the two percent signs are necessary inside of a DOS Batch file. On a regular command prompt, eliminate one of the percent signs. I always use full paths inside of automated scripts to operate under the assumption that the same PATH statements differ between my automated scripts account and my general user accounts. Not including the full paths has been the source of a number of headaches for several developers I have worked with in the past, so I try not to fall into the same pitfall whenever possible. There are a few other tips for using Cygwin in scripting feeds and file transfers, but I will save them for another article.)
Thursday, December 15, 2005
Javascript Input Validation
Previously I had written about input validation in ASP .Net. Since then, I have had a few inquiries regarding input validation using basic JavaScript. In this article I will give a simple example using JavaScript to validate a form input to allow only numbers. First, a warning. Do not rely on Client Side Validation as the only form of input validation for any application. Client side validation can easily be circumvented, causing undesirable results in your application, and lead to possible exploitation in this design vulnerability. Always have some server side validation routine to work with client side validation at the very least, even in a trusted environment.
The goal here is to have a simple form field, with 2 regular un-validated text inputs and 1 validated text inputs. Any non-numeric characters entered into the form field will be cause the Submit action to fail. Validations will only take place on submit to avoid annoying the user with alert boxes on every key press. The code is below
<html>
<head>
<title>Javascript Form Validation with Regular Expression Test</title>
<script language="JavaScript" type="text/JavaScript">
<!--
//Function to validate the input
function validate()
{
//If anything in our string is not a number, fail validation
if (!document.form1.input_field.value.match(/^\d+$/))
{
//Let the user know they put in bad input, and give focus to the
//field to be corrected
alert('invalid input, only numbers allowed');
document.form1.input_field.value = "";
document.form1.input_field.focus();
//Return false
return false;
}
return true;
}
//-->
</script>
</head>
<body>
<!-- This is the form to be validated, it has two BS text fields (we do not validate), and one
field that will be validated, specify the validation function as the submit action -->
<form name="form1" method="post" action="" onSubmit="return validate();">
BS Field
<input type="text" name="textfield1">
<br>
BS Field
<input type="text" name="textfield2">
<br>
Important field
<input name="input_field" type="text">
<br>
<input type="submit" name="Submit" value="Submit">
</form>
</body>
</html>
Very simple. Of course, more complex validations can take place using better regular expressions. For example, thanks to a thread on the Regular Expression Library, the above example can be modified to validate Social Security Numbers using regular expressions in JavaScript. The modified validate function is below:
//Function to validate the input
function validate()
{
//If anything in our string is not a number, fail validation
if (!document.form1.input_field.value.match(/^(?!000)(?!588)(?!666)(?!69[1-9])(?!73[4-9]|7[4-5]\d|76[0123])([0-6]\d{2}|7([0-6]\d|7[012]))([ -])?(?!00)\d\d\3(?!0000)\d{4}$/))
{
//Let the user know they put in bad input, and give focus to the
//field to be corrected
alert('Invalid SSN format');
document.form1.input_field.value = "";
document.form1.input_field.focus();
//Return false
return false;
}
return true;
}
The goal here is to have a simple form field, with 2 regular un-validated text inputs and 1 validated text inputs. Any non-numeric characters entered into the form field will be cause the Submit action to fail. Validations will only take place on submit to avoid annoying the user with alert boxes on every key press. The code is below
<html>
<head>
<title>Javascript Form Validation with Regular Expression Test</title>
<script language="JavaScript" type="text/JavaScript">
<!--
//Function to validate the input
function validate()
{
//If anything in our string is not a number, fail validation
if (!document.form1.input_field.value.match(/^\d+$/))
{
//Let the user know they put in bad input, and give focus to the
//field to be corrected
alert('invalid input, only numbers allowed');
document.form1.input_field.value = "";
document.form1.input_field.focus();
//Return false
return false;
}
return true;
}
//-->
</script>
</head>
<body>
<!-- This is the form to be validated, it has two BS text fields (we do not validate), and one
field that will be validated, specify the validation function as the submit action -->
<form name="form1" method="post" action="" onSubmit="return validate();">
BS Field
<input type="text" name="textfield1">
<br>
BS Field
<input type="text" name="textfield2">
<br>
Important field
<input name="input_field" type="text">
<br>
<input type="submit" name="Submit" value="Submit">
</form>
</body>
</html>
Very simple. Of course, more complex validations can take place using better regular expressions. For example, thanks to a thread on the Regular Expression Library, the above example can be modified to validate Social Security Numbers using regular expressions in JavaScript. The modified validate function is below:
//Function to validate the input
function validate()
{
//If anything in our string is not a number, fail validation
if (!document.form1.input_field.value.match(/^(?!000)(?!588)(?!666)(?!69[1-9])(?!73[4-9]|7[4-5]\d|76[0123])([0-6]\d{2}|7([0-6]\d|7[012]))([ -])?(?!00)\d\d\3(?!0000)\d{4}$/))
{
//Let the user know they put in bad input, and give focus to the
//field to be corrected
alert('Invalid SSN format');
document.form1.input_field.value = "";
document.form1.input_field.focus();
//Return false
return false;
}
return true;
}
Tuesday, December 13, 2005
More OpenOffice.org Macros
While waiting for an excessively long Oracle script to run, I had more time to play around with OpenOffice.org Macros. Have I mentioned how bad the documentation is for OpenOffice? Personally I have very little gripe with OO outside of its incomplete documentation for developers, however some people take their complaints a little further (I agree with a lot of what this guy is saying). I would like to thank Andrew Pitonyak for all his help on the code to select a whole row, and the documentation provided from his site that helped me figure out how to search a document for a value, as well as talking about the undocumented SearchType property used in my example. The below is along the same lines as my previous delete range example, it will search an OpenOffice.org Calc spreadsheet for a matching value and delete the row.
The code is below:
Sub FindAndDeleteRowWithMatch()
Dim oSheet as object
dim oRow as object
dim oCell as object
Dim oDescriptor as object
Dim oFound as object
'Get the first sheet in the active document
oSheet = ThisComponent.getSheets().getByIndex(0)
''Create the search descriptor to searcht eh document
oDescriptor = oSheet.createSearchDescriptor()
'Set the text for which to search and other
'http://api.openoffice.org/docs/common/ref/com/sun/star/util/SearchDescriptor.html
With oDescriptor
.SearchString = "100" 'Search for the formula result value of 100
.SearchWords = True 'Search the whole cell, not just part of it
.SearchCaseSensitive = False 'Do not be case sensitive
.SearchType = 1 'Search for values, not just formulas. This is an undocumented property
End With
'Get the first result from the search
oFound = oSheet.findFirst(oDescriptor)
'If the object is not null or empty, process, otherwise, do not process
if IsEmpty(oFound) or IsNull(oFound) then
print "Not Found"
else
'Get the row with the result in it
oRow = oFound.getRows().getByIndex(0)
'Select the row
ThisComponent.getCurrentController().select(oRow)
'Delete the row from the worksheet
osheet.removeRange(oRow.RangeAddress, com.sun.star.sheet.CellDeleteMode.UP)
'Inform the user that the row was deleted
print "Found and Deleted"
end if
End Sub
This is great, but I decided to extend this just a tad bit more. I wanted to have the same sort of macro as illustrated in my article about the Excel Macro to delete the non-matches from a VLOOKUP. The macro will search the spreadsheet for all values from a VLOOKUP where there is no match and the returned result is “#N/A”. However I ran into an interesting problem. OpenOffice.org does not consider the “#N/A” result from a VLOOKUP a value, so you cannot search for it, nor does it provide a function to search by error codes. This made things a little difficult. Thanks to Andrew Pitonyaks documentation, I was easily able to find a macro that will select a whole sheet as a range, and go through cell by cell to find the matching error code for the “#N/A” value and delete the target row. In the below example I have a simple sheet with a few values, and a VLOOKUP function to compare against the values in another sheet.
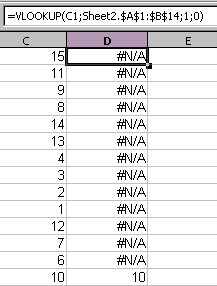
Below is the code based off of the macro found in Andrew Pitonyaks documentation (thanks to Gerrit Jasper for providing the original code).
sub FindNAandDelete()
Dim nCurCol As Integer
Dim nCurRow As Integer
Dim nEndCol As Integer
Dim nEndRow As Integer
Dim oCell As Object
Dim oCursor As Object
Dim aAddress As Variant
Dim iFind As integer
dim oSheet as object
'This is the error value for N/A when a VLOOKUP cannot find a value
const NA_VALUE as integer = 32767
'Get the first sheet in the active document
oSheet = ThisComponent.getSheets().getByIndex(0)
'Select the range to search
oCell = oSheet.GetCellbyPosition( 0, 0 )
oCursor = oSheet.createCursorByRange(oCell)
oCursor.GotoEndOfUsedArea(True)
aAddress = oCursor.RangeAddress
nEndRow = aAddress.EndRow
nEndCol = aAddress.EndColumn
For nCurCol = 0 To nEndCol 'Go through the range column by column,
For nCurRow = 0 To nEndRow 'row by row.
'Get the current cell, then assign its error value
oCell = oSheet.GetCellByPosition( nCurCol, nCurRow )
iFind = oCell.getError()
'If the value matches the NA Value, then we have a match, select and delete the row
If iFind = NA_VALUE then
oRow = oCell.getRows().getByIndex(0)
'Select the row
ThisComponent.getCurrentController().select(oRow)
'delete the selected row
osheet.removeRange(oRow.RangeAddress, com.sun.star.sheet.CellDeleteMode.UP)
'Go back 1 row so we do not miss any values
nCurRow = nCurRow - 1
End If
Next
Next
End sub
Below is a screenshot of the sheet after the macro was run.
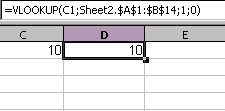
As you can see, it removed all the rows with “#N/A”. While it is not as efficient as I would like, it does do the job. So far, I have found that OO is definitely workable, albeit a little frustrating to work with. Thanks to community support, however, I have not run into an issue yet that I have not been able to work around.
The code is below:
Sub FindAndDeleteRowWithMatch()
Dim oSheet as object
dim oRow as object
dim oCell as object
Dim oDescriptor as object
Dim oFound as object
'Get the first sheet in the active document
oSheet = ThisComponent.getSheets().getByIndex(0)
''Create the search descriptor to searcht eh document
oDescriptor = oSheet.createSearchDescriptor()
'Set the text for which to search and other
'http://api.openoffice.org/docs/common/ref/com/sun/star/util/SearchDescriptor.html
With oDescriptor
.SearchString = "100" 'Search for the formula result value of 100
.SearchWords = True 'Search the whole cell, not just part of it
.SearchCaseSensitive = False 'Do not be case sensitive
.SearchType = 1 'Search for values, not just formulas. This is an undocumented property
End With
'Get the first result from the search
oFound = oSheet.findFirst(oDescriptor)
'If the object is not null or empty, process, otherwise, do not process
if IsEmpty(oFound) or IsNull(oFound) then
print "Not Found"
else
'Get the row with the result in it
oRow = oFound.getRows().getByIndex(0)
'Select the row
ThisComponent.getCurrentController().select(oRow)
'Delete the row from the worksheet
osheet.removeRange(oRow.RangeAddress, com.sun.star.sheet.CellDeleteMode.UP)
'Inform the user that the row was deleted
print "Found and Deleted"
end if
End Sub
This is great, but I decided to extend this just a tad bit more. I wanted to have the same sort of macro as illustrated in my article about the Excel Macro to delete the non-matches from a VLOOKUP. The macro will search the spreadsheet for all values from a VLOOKUP where there is no match and the returned result is “#N/A”. However I ran into an interesting problem. OpenOffice.org does not consider the “#N/A” result from a VLOOKUP a value, so you cannot search for it, nor does it provide a function to search by error codes. This made things a little difficult. Thanks to Andrew Pitonyaks documentation, I was easily able to find a macro that will select a whole sheet as a range, and go through cell by cell to find the matching error code for the “#N/A” value and delete the target row. In the below example I have a simple sheet with a few values, and a VLOOKUP function to compare against the values in another sheet.
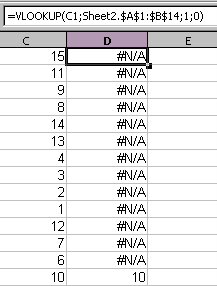
Below is the code based off of the macro found in Andrew Pitonyaks documentation (thanks to Gerrit Jasper for providing the original code).
sub FindNAandDelete()
Dim nCurCol As Integer
Dim nCurRow As Integer
Dim nEndCol As Integer
Dim nEndRow As Integer
Dim oCell As Object
Dim oCursor As Object
Dim aAddress As Variant
Dim iFind As integer
dim oSheet as object
'This is the error value for N/A when a VLOOKUP cannot find a value
const NA_VALUE as integer = 32767
'Get the first sheet in the active document
oSheet = ThisComponent.getSheets().getByIndex(0)
'Select the range to search
oCell = oSheet.GetCellbyPosition( 0, 0 )
oCursor = oSheet.createCursorByRange(oCell)
oCursor.GotoEndOfUsedArea(True)
aAddress = oCursor.RangeAddress
nEndRow = aAddress.EndRow
nEndCol = aAddress.EndColumn
For nCurCol = 0 To nEndCol 'Go through the range column by column,
For nCurRow = 0 To nEndRow 'row by row.
'Get the current cell, then assign its error value
oCell = oSheet.GetCellByPosition( nCurCol, nCurRow )
iFind = oCell.getError()
'If the value matches the NA Value, then we have a match, select and delete the row
If iFind = NA_VALUE then
oRow = oCell.getRows().getByIndex(0)
'Select the row
ThisComponent.getCurrentController().select(oRow)
'delete the selected row
osheet.removeRange(oRow.RangeAddress, com.sun.star.sheet.CellDeleteMode.UP)
'Go back 1 row so we do not miss any values
nCurRow = nCurRow - 1
End If
Next
Next
End sub
Below is a screenshot of the sheet after the macro was run.

As you can see, it removed all the rows with “#N/A”. While it is not as efficient as I would like, it does do the job. So far, I have found that OO is definitely workable, albeit a little frustrating to work with. Thanks to community support, however, I have not run into an issue yet that I have not been able to work around.
Tuesday, December 06, 2005
First Foray into OpenOffice.org Macro Programming
I have begun working with OpenOffice.org 2.0 macros, and all I have to say is “ouch”, my first experience was not a positive one. I do have a couple of macros that do their intended purpose, but I also have one hell of a headache. I love OpenOffice, it is a great product, but its macro facilities have a long way to go before being considered prime time. The biggest problem is the lack of documentation for any of their objects. While http://api.openoffice.org/ has an API reference, it is cumbersome to find information, forcing you to use the search feature. It is not quite the reference at my fingertips that it should be. This experience has not deterred me from learning how to develop for OpenOffice however, but I do have some major gripes. Thankfully I came across websites of people who have been down this road before, which somewhat got me started in the right direction.
-OpenOffice Basic Macro for Calc (the guy has a few macros for demonstration, he seems to agree about the documentation)
-OpenOffice Tips (probably the first site I found that helped me get a handle on accessing basic things like Cells access)
-Excel VBA to Calc/StarBasic
-OpenOffice API Homepage
My intended goal was to write macros that would do simple tasks first, so the macro I wrote is for Calc and will select a range and delete it. This will work for deleting rows and columns. Below are two different versions, one will simply clear the contents, and the other will delete the range.
Clear the range:
Sub clear_range
'Generic objects for selecting the current document,
'worksheet, and storing the range
Dim oDoc As Object
Dim oSheet As Object
Dim oRange As Object
'Integer for setting the various attributes to clear values
Dim iCellAttr As Integer
'Set all attributes for clearing
iCellAttr = _
com.sun.star.sheet.CellFlags.VALUE + _
com.sun.star.sheet.CellFlags.DATETIME + _
com.sun.star.sheet.CellFlags.STRING + _
com.sun.star.sheet.CellFlags.ANNOTATION + _
com.sun.star.sheet.CellFlags.FORMULA + _
com.sun.star.sheet.CellFlags.HARDATTR + _
com.sun.star.sheet.CellFlags.STYLES + _
com.sun.star.sheet.CellFlags.OBJECTS + _
com.sun.star.sheet.CellFlags.EDITATTR
'Set the current documents
oDoc=ThisComponent
'Get the sheet to clear the range, then select that range and clear
oSheet=oDoc.Sheets.getByName("Sheet1")
oRange=oSheet.getCellRangeByName("A1:B7")
'Clear the range based on the attributes set to clear
oRange.ClearContents(iCellAttr)
End Sub
Delete the range:
Sub delete_range
'Generic objects for selecting the current document,
'worksheet, and storing the range
Dim oDoc As Object
Dim oSheet As Object
Dim oRange As Object
'Set the current documents
oDoc=ThisComponent
'Get the sheet to clear the range, then select that range and clear
oSheet=oDoc.Sheets.getByName("Sheet1")
oRange=oSheet.getCellRangeByName("A1:B7")
‘Delete the range
osheet.removeRange(oRange.RangeAddress, com.sun.star.sheet.CellDeleteMode.UP)
End Sub
I could not find a easier way to select rows or columns other than to select a large range of cells, so if you know of one, please share.
If you are setting out to do some work with OpenOffice.org macro facilities, be sure to keep plenty of patience handy, because your going to need it.
Update: I found this very useful document on Andrew Pitonyak website. He is the author of OpenOffice.org Macros Explained. Apparently this document was not up at the time of this writing. But I found tons of useful information in it. Thanks Andrew for posting it.
-OpenOffice Basic Macro for Calc (the guy has a few macros for demonstration, he seems to agree about the documentation)
-OpenOffice Tips (probably the first site I found that helped me get a handle on accessing basic things like Cells access)
-Excel VBA to Calc/StarBasic
-OpenOffice API Homepage
My intended goal was to write macros that would do simple tasks first, so the macro I wrote is for Calc and will select a range and delete it. This will work for deleting rows and columns. Below are two different versions, one will simply clear the contents, and the other will delete the range.
Clear the range:
Sub clear_range
'Generic objects for selecting the current document,
'worksheet, and storing the range
Dim oDoc As Object
Dim oSheet As Object
Dim oRange As Object
'Integer for setting the various attributes to clear values
Dim iCellAttr As Integer
'Set all attributes for clearing
iCellAttr = _
com.sun.star.sheet.CellFlags.VALUE + _
com.sun.star.sheet.CellFlags.DATETIME + _
com.sun.star.sheet.CellFlags.STRING + _
com.sun.star.sheet.CellFlags.ANNOTATION + _
com.sun.star.sheet.CellFlags.FORMULA + _
com.sun.star.sheet.CellFlags.HARDATTR + _
com.sun.star.sheet.CellFlags.STYLES + _
com.sun.star.sheet.CellFlags.OBJECTS + _
com.sun.star.sheet.CellFlags.EDITATTR
'Set the current documents
oDoc=ThisComponent
'Get the sheet to clear the range, then select that range and clear
oSheet=oDoc.Sheets.getByName("Sheet1")
oRange=oSheet.getCellRangeByName("A1:B7")
'Clear the range based on the attributes set to clear
oRange.ClearContents(iCellAttr)
End Sub
Delete the range:
Sub delete_range
'Generic objects for selecting the current document,
'worksheet, and storing the range
Dim oDoc As Object
Dim oSheet As Object
Dim oRange As Object
'Set the current documents
oDoc=ThisComponent
'Get the sheet to clear the range, then select that range and clear
oSheet=oDoc.Sheets.getByName("Sheet1")
oRange=oSheet.getCellRangeByName("A1:B7")
‘Delete the range
osheet.removeRange(oRange.RangeAddress, com.sun.star.sheet.CellDeleteMode.UP)
End Sub
I could not find a easier way to select rows or columns other than to select a large range of cells, so if you know of one, please share.
If you are setting out to do some work with OpenOffice.org macro facilities, be sure to keep plenty of patience handy, because your going to need it.
Update: I found this very useful document on Andrew Pitonyak website. He is the author of OpenOffice.org Macros Explained. Apparently this document was not up at the time of this writing. But I found tons of useful information in it. Thanks Andrew for posting it.
Monday, December 05, 2005
Secure Programming - C/C++ Strings
Thanks to OSNews.com for posting this sample chapter from “Secure Coding in C/C++” about common pitfalls with Strings in C/C++. While this is an age-old discussion, it’s obviously still valid since these issues still exist in modern software. If a more appropriate higher level language with an actual string type is available, it should be used. Knowing which tools to use and when to use them is an important aspect of being a developer. Experience and dogma have not made developers immune from mistakes and this article has great information on various types of issues that can arise from character arrays, different stack protection routines, and even the venerable std::basic_string class. I was unaware of the Stack Smashing Protector for GCC. Funny that this was released at this time, I was going to write an article demonstrating buffer overflows for a future article. With this sample chapter and a little old Phrack Article, I have a great base to start from.
Thursday, December 01, 2005
Comments and Classes
I came across this article entitled “How to Write Comments”. I feel that generally this is really good advice. However, the author intermingles the topics of good commenting and object design, which are not the same thing. These are topics that cannot be fully addressed in a single article, so I will only touch on them.
There seems to be debate as to the “reason” why you comment your code. Personally, I don’t think there should be question as to why you write you comments, you just do it. Code is easier to understand, is more maintainable, and typically is better quality when commented. If I had to give a single reason, I would have to agree with the author that the primary reason is for readability of the code, whether it is for other coders, or for yourself. How many times have you had to revisit some piece of code you wrote a long time ago, and had to ask yourself “What the hell was I thinking?” Imagine that another coder had to figure that out. I try to imagine that everyone’s time is as limited as mine, which means they don’t have time to trace through code to figure out some ridiculous algorithm. While commenting is definitely and important aspect of design, I rank readability higher. I feel that design should be done separately through flow charts, pseudo-code, or UML and transitioned to comments before writing code. This is especially true for larger projects where tasks are broken up among individuals where the program flow is designed in a case tool and the programmers are simply typing it in and debugging.
Unfortunately, modern languages are not as verbose as languages like COBOL. COBOL is a wordy language, with very descriptive syntax. Languages like Java and C make commenting even more necessary for understanding the logic due to their use of symbols and their syntactical flexibility. My rule of thumb is to comment blocks of code accomplishing a single task in the problem solving steps. Some argue for very verbose commenting, some argue for less. I say use as much wording as is necessary to fully describe the task, and if possible, why are you using that approach. For example, lets say we had an object that handles connections to a database. Establishing a connection to the database is a single step in the overall algorithm, however it requires several steps of its own. So a single, descriptive comment telling a reader that you are setting the required properties and establishing the database connection would precede the series of lines. Below are two examples using the fictitious object to establish a database connection demonstrating commenting to describe what is being done.
Ex 1:
//Establish a database connection using the connect call, passing in the user name
//password, and database to connect to. This is done to avoid overhead of calling
//the separate set functions for the three properties and to take advantage of the
//error handling built in to the overloaded connect method
data_object->connect(“user”, “password”, “OracleInstance1”);
Ex 2:
//A database connection is established by setting the user name, password,
//and database name, then calling the connect method. This is done separately
//for readability and clarity on the separate steps and to isolate data assignment
//errors from database connection errors
Data_object->setUserName(“user”);
Data_object->setPassword(“password”);
Data_object->setDatabase(“OracleInstance1”);
Data_object->connect();
The above examples explain what the code is doing, and why.
Object design is another issue altogether. Understanding what objects are goes a long way to writing good objects. Objects are “abstractions of real world objects” that “know things” (properties) and “knows how to do things” (methods) (The Object-Oriented Approach: Concepts, Systems Development, and Modeling with UML page 17). This is one of the best definitions I have ever read for the definition of an object. Objects can be a representation in the system of anything, such as an airplane, care, disk drive, incident, or location. Classes are definitions of those objects. Objects are implementations of classes. These terms are used inappropriately used interchangeably sometimes. However if you understand those definitions, you can derive their meaning from the context. Books are written about good object design principles, so I will not go in to depth.
I agree with the author that objects should be describable in one “noun”, I question “verb” since actions are supposed to be reserved for methods, but I will concede that for the time being. Lets look at an example. Here is a simple event class from some sort of event generator. Events have a description, unique id, and a timestamp. These are the properties of the Event object. In the context of our system, the Event class will also need to know how to write the event out to a database, read an event in from a database, and generate the unique ID. These are the methods. The database related methods will be exposed for public use since we want the outside world to interact with those methods. The outside world does not care how the unique ID is generated, so it will be private. We will also need methods to set and return the values in our properties. This is the preferred method for exposing properties since it allows for type checking, error handling, possible logic built into property assignment, and to allow properties to be read-only or write-only. The class definition in C++ would look something like this:
//This class will handle Events from our fictitious event system
class event{
private:
//variables relating to the event
string p_unique_id; //the ID for this events
string p_description; //What is the actual alert message
time_t p_timestamp; //when did the event occur
//internal function to generate the ID for a new event
string generate_unique_id();
public:
//public methods exposing the properties of the event
string get_unique_id();
string get_description();
string get_timestamp();
//public methods allowing for assignment of properties
int set_unique_id(const string &);
int set_description(const string &);
int set_timestamp(const string &);
//methods to work with a database for events
int retrieve_Event_from_Database(string &);
int insert_Event_into_Database();
};
In the above, what the object “knows”, and what it “knows how to do” are clearly defined. As a developer, I can interact with that object through its exposed methods, and the implementation is taken care of behind the scenes. I don’t care how it does it, as long as it does what it is supposed to do. A good class should shield me from the specifics, and do one thing and do it really well. The above class is simple and handles only one simple abstraction.
One of the biggest issues with Object Oriented Analysis and Design comes from choosing an OO language where it is not the appropriate language of choice for a project. OOAD has been touted as “The Way” for so long that people try to kludge it to scenarios where is not appropriate. For a simple program to run a sequence of steps, a scripting language would be more appropriate. For a low-level operating system driver handling a device or a tightly constrained program running on an embedded device, assembler or C would be more appropriate. For a simple piece of office software like a clock in/clock out program, Visual Basic would be more appropriate. For a system representing real world objects and procedures, an OO based language like C++ or Java would definitely fit. Knowing which scenarios to apply OO design concepts is essential to design. OO programming is not the end all answer to all software design issues; it is merely another tool in the developer’s toolkit.
 There are several tools for working with OOAD models. The most robust one I have worked with is Rational Rose. However, Rose has a hefty price tag well outside most consumers. My alternative favorite is Umbrello, which is now included in the KDE SDK. I use it both under Linux and under Windows using Cygwin and it works very well, and includes a basic code generator. Visio also has stencils for UML models, although I only use Visio for flowcharts when Dia is unavailable.
There are several tools for working with OOAD models. The most robust one I have worked with is Rational Rose. However, Rose has a hefty price tag well outside most consumers. My alternative favorite is Umbrello, which is now included in the KDE SDK. I use it both under Linux and under Windows using Cygwin and it works very well, and includes a basic code generator. Visio also has stencils for UML models, although I only use Visio for flowcharts when Dia is unavailable.
There seems to be debate as to the “reason” why you comment your code. Personally, I don’t think there should be question as to why you write you comments, you just do it. Code is easier to understand, is more maintainable, and typically is better quality when commented. If I had to give a single reason, I would have to agree with the author that the primary reason is for readability of the code, whether it is for other coders, or for yourself. How many times have you had to revisit some piece of code you wrote a long time ago, and had to ask yourself “What the hell was I thinking?” Imagine that another coder had to figure that out. I try to imagine that everyone’s time is as limited as mine, which means they don’t have time to trace through code to figure out some ridiculous algorithm. While commenting is definitely and important aspect of design, I rank readability higher. I feel that design should be done separately through flow charts, pseudo-code, or UML and transitioned to comments before writing code. This is especially true for larger projects where tasks are broken up among individuals where the program flow is designed in a case tool and the programmers are simply typing it in and debugging.
Unfortunately, modern languages are not as verbose as languages like COBOL. COBOL is a wordy language, with very descriptive syntax. Languages like Java and C make commenting even more necessary for understanding the logic due to their use of symbols and their syntactical flexibility. My rule of thumb is to comment blocks of code accomplishing a single task in the problem solving steps. Some argue for very verbose commenting, some argue for less. I say use as much wording as is necessary to fully describe the task, and if possible, why are you using that approach. For example, lets say we had an object that handles connections to a database. Establishing a connection to the database is a single step in the overall algorithm, however it requires several steps of its own. So a single, descriptive comment telling a reader that you are setting the required properties and establishing the database connection would precede the series of lines. Below are two examples using the fictitious object to establish a database connection demonstrating commenting to describe what is being done.
Ex 1:
//Establish a database connection using the connect call, passing in the user name
//password, and database to connect to. This is done to avoid overhead of calling
//the separate set functions for the three properties and to take advantage of the
//error handling built in to the overloaded connect method
data_object->connect(“user”, “password”, “OracleInstance1”);
Ex 2:
//A database connection is established by setting the user name, password,
//and database name, then calling the connect method. This is done separately
//for readability and clarity on the separate steps and to isolate data assignment
//errors from database connection errors
Data_object->setUserName(“user”);
Data_object->setPassword(“password”);
Data_object->setDatabase(“OracleInstance1”);
Data_object->connect();
The above examples explain what the code is doing, and why.
Object design is another issue altogether. Understanding what objects are goes a long way to writing good objects. Objects are “abstractions of real world objects” that “know things” (properties) and “knows how to do things” (methods) (The Object-Oriented Approach: Concepts, Systems Development, and Modeling with UML page 17). This is one of the best definitions I have ever read for the definition of an object. Objects can be a representation in the system of anything, such as an airplane, care, disk drive, incident, or location. Classes are definitions of those objects. Objects are implementations of classes. These terms are used inappropriately used interchangeably sometimes. However if you understand those definitions, you can derive their meaning from the context. Books are written about good object design principles, so I will not go in to depth.
I agree with the author that objects should be describable in one “noun”, I question “verb” since actions are supposed to be reserved for methods, but I will concede that for the time being. Lets look at an example. Here is a simple event class from some sort of event generator. Events have a description, unique id, and a timestamp. These are the properties of the Event object. In the context of our system, the Event class will also need to know how to write the event out to a database, read an event in from a database, and generate the unique ID. These are the methods. The database related methods will be exposed for public use since we want the outside world to interact with those methods. The outside world does not care how the unique ID is generated, so it will be private. We will also need methods to set and return the values in our properties. This is the preferred method for exposing properties since it allows for type checking, error handling, possible logic built into property assignment, and to allow properties to be read-only or write-only. The class definition in C++ would look something like this:
//This class will handle Events from our fictitious event system
class event{
private:
//variables relating to the event
string p_unique_id; //the ID for this events
string p_description; //What is the actual alert message
time_t p_timestamp; //when did the event occur
//internal function to generate the ID for a new event
string generate_unique_id();
public:
//public methods exposing the properties of the event
string get_unique_id();
string get_description();
string get_timestamp();
//public methods allowing for assignment of properties
int set_unique_id(const string &);
int set_description(const string &);
int set_timestamp(const string &);
//methods to work with a database for events
int retrieve_Event_from_Database(string &);
int insert_Event_into_Database();
};
In the above, what the object “knows”, and what it “knows how to do” are clearly defined. As a developer, I can interact with that object through its exposed methods, and the implementation is taken care of behind the scenes. I don’t care how it does it, as long as it does what it is supposed to do. A good class should shield me from the specifics, and do one thing and do it really well. The above class is simple and handles only one simple abstraction.
One of the biggest issues with Object Oriented Analysis and Design comes from choosing an OO language where it is not the appropriate language of choice for a project. OOAD has been touted as “The Way” for so long that people try to kludge it to scenarios where is not appropriate. For a simple program to run a sequence of steps, a scripting language would be more appropriate. For a low-level operating system driver handling a device or a tightly constrained program running on an embedded device, assembler or C would be more appropriate. For a simple piece of office software like a clock in/clock out program, Visual Basic would be more appropriate. For a system representing real world objects and procedures, an OO based language like C++ or Java would definitely fit. Knowing which scenarios to apply OO design concepts is essential to design. OO programming is not the end all answer to all software design issues; it is merely another tool in the developer’s toolkit.
 There are several tools for working with OOAD models. The most robust one I have worked with is Rational Rose. However, Rose has a hefty price tag well outside most consumers. My alternative favorite is Umbrello, which is now included in the KDE SDK. I use it both under Linux and under Windows using Cygwin and it works very well, and includes a basic code generator. Visio also has stencils for UML models, although I only use Visio for flowcharts when Dia is unavailable.
There are several tools for working with OOAD models. The most robust one I have worked with is Rational Rose. However, Rose has a hefty price tag well outside most consumers. My alternative favorite is Umbrello, which is now included in the KDE SDK. I use it both under Linux and under Windows using Cygwin and it works very well, and includes a basic code generator. Visio also has stencils for UML models, although I only use Visio for flowcharts when Dia is unavailable.
Subscribe to:
Posts (Atom)

