I often hear the terms “vulnerability” and “exploit”, and I automatically assume the worse. I suppose I have been paying too much attention to the security world too long. But, there are times where “exploiting vulnerabilities” is not a bad thing, and actual positive end results can result. This is the with the PSP home brew software scene.
You see, I scored a PSP in a contest I had entered. I was aware that a lot of cool things that can be done with the PSP, and now I finally had a chance to give them a try. The first thing that I needed, was the find out which version of the PSP firmware I was running. Since I last checked, which was a year, maybe two years ago, the only version that could be taken advantage of was the 1.0 firmware. I was running the 2.6 firmware, as indicated by the System Information menu under the PSP system menu, accessible by either starting the PSP without a game in the loader, or by hitting the Home button while a game is running. After a little bit of research, I found out there is a vulnerability in the Grand Theft Auto: Liberty City Stories game that allows for the loading of what is called an eBoot loader. So I needed an eBoot loader.
The eBoot loader (now called an eLoader) that I came across is called the eLoader 0.97, available here. The instructions for loading this are included with the download files. It basically consists of just unextracting the files to the memory stick, done by connecting the PSP to a PC via the USB cable. Once completed, I needed the exploit for GTA. I have read that newer version of GTA have fixed the security hole, however I fortunately had a vulnerable version. The exploit is basically a special saved game that will start the eLoader when the save game is loaded. The exploit is included with the eLoader 0.97 download. Basically just extract the archive to the memory stick and your good to go. When you launch GTA, just load the saved game, and the eLoader will execute. Now you need some home brew apps. I recommend getting the SNES, NES, and Genesis Emulators. I did not have good success with the Game Boy Advance emulator. Perhaps people who downgrade their firmware have better luck, but there is a slight chance of bricking the PSP, so I won't take it. However, I hear there is high success.
Working on a presentation I am giving, I needed to export my existing Sguil Database to my laptop. I have years of data in this database, so it provides a good basis for demonstrating some basic reporting principles in BIRT. So I needed to export the data to my local system.
This is actually a very easy thing to accomplish. On the source system, I run the following command:
mysqldump -u -p sguildb > sguildb.sql
Where -u is a switch to accept the database username to use, -p will prompt for a password, and the last entry is the database to export, in this case the sguildb database. Now, I have a large script that will rebuild the Sguil database on my development system in my user directory.
I log into the target system, and copy the script using the following command:
scp @:sguildb.sql
This will use the secure copy command to copy the sguildb.sql file from my source system to the local target system.
In order to import, I run the following command:
cat sguildb.sql | mysql -p -D sguildb
Where -p will prompt for a password, and -D is the database switch. I do not use the username switch since I am using my local user account name to login to the database.
Another thing I have been playing with is XML using Apache Xerces. I plan to use XML files to store configuration information for programs. I also use several programs that use XML as a data file formats, and I need an easy way to parse various info from them. The following example will write out an XML file with a structure like so:
Previously I had posted that I had figured out how why I couldn't make JDBC connections to OpenOffice.org files. Now, I wrote the solution. The following example will open an OpenOffice.org Base file via the Java ZIP classes, extract the necessary files to the temporary folder and extract the necessary files, create the JDBC connection using the HSQLDB JDBC driver, query, then delete the temp files. The file in question is located at ~/OODatabase/employeeDatabase.odb. The query will get the first names and last names (nm_emp_first, nm_emp_last respectivly) from the database.
import java.sql.*; import java.util.zip.*; import java.io.*; import org.hsqldb.jdbcDriver; import java.util.*; public class Test { public static void main(String[] args) { jdbcDriver j = new jdbcDriver(); //Instantiate the jdbcDriver from HSQL Connection con = null; //Database objects Statement com = null; ResultSet rec = null; ZipFile file = null; //For handeling zip files ZipEntry ent = null; Enumeration en = null; //For the entries in the zip file BufferedOutputStream out = null; //For the output from the zip class InputStream in = null; //for reading buffers from the zip file File f = null; //Used to get a temporary file name, not actually used for anything int len; //General length counter for loops List v = new ArrayList(); //Stores list of unzipped file for deletion at end of program //Unzip zip file, via info from //http://www.devx.com/getHelpOn/10MinuteSolution/20447 try { //Open the zip file that holds the OO.Org Base file file = new ZipFile("/home/digiassn/OODatabase/employeeDatabase.odb"); //Create a generic temp file. I only need to get the filename from //the tempfile to prefix the extracted files for OO Base f = File.createTempFile("ooTempDatabase", "tmp"); f.deleteOnExit(); //Get file entries from the zipfile and loop through all of them en = file.entries(); while (en.hasMoreElements()) { //Get the current element ent = (ZipEntry)en.nextElement(); //If the file is in the database directory, extract it to our //temp folder using the temp filename above as a prefix if (ent.getName().startsWith("database/")) { System.out.println("Extracting File: " + ent.getName()); byte[] buffer = new byte[1024]; //Create an input stream file the file entry in = file.getInputStream(ent); //Create a output stream to write out the entry to, using the //temp filename created above out = new BufferedOutputStream(new FileOutputStream("/tmp/" + f.getName() + "." + ent.getName().substring(9))); //Add the newly created temp file to the tempfile vector for deleting //later on v.add("/tmp/" + f.getName() + "." + ent.getName().substring(9)); //Read the input file into the buffer, then write out to //the output file while((len = in.read(buffer)) >= 0) out.write(buffer, 0, len); //close both the input stream and the output stream out.close(); in.close(); } } //Close the zip file since the temp files have been created file.close(); //Create our JDBC connection based on the temp filename used above con = DriverManager.getConnection("jdbc:hsqldb:file:/tmp/" + f.getName(), "SA", ""); //Create a command object and execute, storing the results in the rec object com = con.createStatement(); rec = com.executeQuery("select * from \"employees\""); //GO through the resultset, and output the results while (rec.next()) System.out.println("Last Name: " + rec.getString("nm_emp_last") + " First Name: " + rec.getString("nm_emp_first")); //Close all the database objects rec.close(); com.close(); con.close(); //Delete the temporary files, which file names are stored in the v vector for (len = 0; len <> v.size(); len++) (new File((String)v.get(len))).delete(); } catch (Exception e) { e.printStackTrace(); } } }
For the past few weeks I have indulged myself in the wonders of Java programming. For the longest time I had given in to the hype perpetrated by the C/C++ evangelicals, falling victim to misdirection given on the multitude of programming forums. Well, not completely, maybe half-heartedly. The truth is, the more and more I work with Java, the more I find myself preferring it to C’s forced acceptance of low-level details that, when solving an issue in the problem domain not directly related to tight memory constraints or direct hardware access, I really don’t have the time nor desire to really address. This is where Java comes into play. I can look past Java’s heavily Object Oriented bias due to the large native libraries that do so many great things like XML manipulation and Zip file support and the overwhelming number of third libraries such as the Apache and Eclipse libraries. In fact, just this weekend I was incredibly impressed by the ease of creating code to unzip files by using the java.util.zip libraries.
Despite all that praise, I do have one major gripe, which is perhaps a showstopper for my using Java as my day-to-day language. While I understand that one of the major advantages of Java is the ability to compile once and run anywhere, I find it annoying that I cannot compile to my native platform and take the JVM middleman out of the equation. Seriously, why is it ten years later, if not more, and Java still does not have native compilation for a platform of choice. That is the key word after all, choice. While anything below a scripting language needs compilation, Sun is really missing an excellent opportunity. Others have tried such attempts, such as Microsoft’s Java and the GNU Java compiler, their compatibility and support leaves much to be desired. Hell, Microsoft’s piss poor implementation is far behind the Java compatibility curve that their inclusion of it in their developer suite is an insult to the other languages.
Fortunately, there is one product that seems to understand that despite Suns philosophical beliefs, they are not powerful enough to force a paradigm shift away from the .Exe expectancy in Windows users (I omit *nix from these expected .exe paradigms since most a good majority of the users of these platforms are used to using PERL and are aware that scripts can be invoked from the command line via an interpreter call in addition to the first line indicating the interpreter to use). Unfortunately, native compilation comes at a large price, but the product to get the job done is Excelsior’s Jet.
As far as getting the compilation done, Jet provides a very easy to use wizard that walks you through, step by step, how to compile. There are a few caveats. First, the code must already be compiled into a .jar file. Second, you need to know the class path for running the program. For example, to run the CLI example I had previously written about, I would normally run the following command:
Once I input this into the classpath entry and hit the parse button, the program will ask a few more questions, and then parse a native x86 exe file. The only issue is the inclusion of the Jet Runtime in any programs that would be distributed.
That’s the good news, now comes the bad news. The program is expensive. Not as expensive as other compilers, however it is a little pricey for someone who, like me, is a hobbyist, not a professional. I can live with creating batch files to run my Java apps for the cost; however, if I were a professional java developer targeting a specific platform (Windows, Linux, etc) this would be a highly considered addition to my toolkit.
I have been working with trying to get a JDBC connection to an OpenOffice.org database file for the past few days. Using the HSQLDB.jar file included with OpenOffice (OO uses the HSQLDB engine for Base) I have tried everything, and each time I get an error about "no table" with my select statements. I tried creating a new database programatically via JDBC, tried reconnecting, recreating. I researched on the Internet and have found scores of programmers who have the same issue, and yet no solution seems available. Of course, I've commented on the futility of searching the OpenOffice site for answers before. So just when I'm about to give up, I have a hunch and hex-edit the .odb file that OpenOffice creates. Amazingly, it only takes seeing the first two bytes of the file and everything makes sense. When you see that distinctive "PZ" starting a file, its almost like seeing the Coke logo, you immediatly know what your looking at. The reason I can't connect to the database via JDBC is because OpenOffice does not store the files using the file format from HSQL, it uses a ZIP file. I confirm this by running "file .odb", and sure enough, its a zip file. So I unzip the file, and there, lo and behold, are the HSQL database files, along with a bunch of XML files describing things such as forms and queries. Interesting notes, the properties file states that OO uses the HSQL Cached table types. This gives a good indication how I should build my JDBC URL when connecting to these files. Now that one mystery is solved, I can work on connecting via JDBC to these files. I will work on building either a JDBC connector for OpenOffice files for BIRT, or I will make a scripted data connection so that I can use OpenOffice files in BIRT for reporting.
Sometimes you come across something that just really puts the icing on the cake. In this case, it was Easy Ubuntu. I lamented the decision to reformat my desktop system and put Ubuntu on there since I had a nice Debian install configured and ready for me. The hardest part was giving up the nice Nvidia drivers I had already installed. Having to through reconfiguring and reinstalling Kernel modules for this wasn't something I was looking forward to. But I did because I liked Ubuntu so much on my laptop that this seemed the best way to go. Then, as if a light shined down from the computer gods, I was clued in to the existence of Easy Ubuntu. Apparently I am not the only one who wants things like proprietary codecs, DVD playing, and Nvidia/ATI video drivers under Linux. Whats even greater, its only a few button clicks and your up with all the goodies. I opted to install the Nvidia drivers, fonts, Macromedia Flash, DVD playing, and other video codecs. In a few minutes it had it installed. No fuss. While I understand the rationale for not having these things in the Ubuntu base distribution, it would be nice if these things were already included. But oh well, no funky configurations or anything, all manageable and update able from Synaptic from here on out.
Update: err everything above is true, except for the Nvidia drivers install. The drivers from Easy Ubuntu b0rked the X configuration. I had to remove these manually and get the latest drivers from Nvidias website and compile them. Oh well, so much for a perfect plan.
Continuing my adventures in Java land, I decided to embark upon the wild world of JDBC programming. What I have discovered is that JDBC programming is very similar to ADO programming, leading me to believe that Microsoft may have borrowed some of the finer points of Database handleing from the Java crowd. Either way, the methodology is similar:
-Create Connection -Create Statement (a Command in ADO) -Create ResultSet (a RecordSet in ADO)
How interesting. Even the JDBC URL has similarities to the UDL strings that Ado has the ability to use. So from a methodology point of view, this transition was incredibly minor. I wrote a simple demonstration class that will simply get my last name from an employees database using my employee ID. Here I am using the Oracle JDBC driver, which I also had to include in the classpath when compiling the program. Fortunately, Eclipse really makes project management easy in this respect.
package jdbcExample; import java.sql.*; import oracle.jdbc.driver.OracleDriver; import java.util.*; public class JDBCExample { /** * @param args */ public static void main(String[] args) { Connection con = null; Statement stmt = null; ResultSet set = null; OracleDriver orc = null; Driver d = null; java.util.List l; try { //First, print out all drivers that the DriverManager has //registered System.out.print("Before Run: "); l = Collections.list(DriverManager.getDrivers()); //Loop through the collection and print the name of each //driver registered for (int x = 0; x < l.size(); x++) { d = (Driver)l.get(x); System.out.print(d.getClass().getName()); } System.out.println(); //The below commented out line seems to be the prefered method //to instantiate a JDBC driver and register with the DriverManager. //I chose not to use it since it seems to be similar to just instantiating //the driver itself as an object and that form is more familiar. //Class.forName("oracle.jdbc.driver.OracleDriver").newInstance(); //Instantiate the driver and register with the driver class, which is //taken care of automatically upon creation orc = new OracleDriver(); //Get a connection to our database from the drivermanager con = DriverManager.getConnection("jdbc:oracle:thin:@server.com:1521:Database", "USER”, "PASSWORD"); //Display drivers registered after creation and connection System.out.print("After Run: "); l = Collections.list(DriverManager.getDrivers()); for (int x = 0; x < l.size(); x++) { d = (Driver)l.get(x); System.out.println(d.getClass().getName()); } } catch (Exception e) { e.printStackTrace(); System.exit(-1); } //Here, catch any errors executing the query try { //Create a statement object, then execute the select query. stmt = con.createStatement(); set = stmt.executeQuery("select no_emp from employees where no_emp = ‘JW12345’); //Go to the first returned element and display the results set.next(); System.out.println("Query Result: " + set.getString("no_emp")); //Close the connection con.close(); } catch (Exception e) { e.printStackTrace(); System.exit(-1); } } }
Although I had intended to write up an article on this, the folks over at HowTo Forge beat me to it. I will work on installing this next weekend when I import my old Red Hat MySQL database over to my desktop machine for development work.
While continuing to experiment with Java, I needed something to easily parse command line arguments for CLI programs. Fortunately, came across the Apache Projects Commons CLI class. This has to be the easiest way to parse command line interfaces I have come across yet. The concept is pretty simple, you have an Options object that contains Option objects. Each Option is one command line option, either single character, single string, or string/value pairs. You pass the Options object and the command line string to a parser, and you can test against the results to see if certain options were passed. Plus it provides a simple helper to print out usage messages based on options. It is a very simple to use interface. Below is my testing code.
package clitest; import org.apache.commons.cli.*; public class CliTest { public static void main(String[] args) { Option opt = new Option("test", "This is a generic option"); Option message = OptionBuilder.withArgName("message") .hasArg() .withDescription("Message to print") .create("message"); CommandLineParser parser = new GnuParser(); Options options = new Options(); CommandLine line = null; HelpFormatter formatter = new HelpFormatter(); options.addOption(opt); options.addOption(message); if (args.length < 1) { formatter.printHelp( "clitest", options ); System.exit(0); } try { line = parser.parse(options, args); } catch (Exception e) { System.err.println( "Parsing failed. Reason: " + e.getMessage() ); System.exit(-1); } if (line.hasOption("message")) System.out.println(line.getOptionValue("message")); if (line.hasOption("test")) { System.out.println("Test parameter passed"); } } }
Some time ago I wrote a few articles on socket programming under Cygwin and process forking. The intended goal was to tie it all together with a third article about Shared Memory and IPC and demonstrate a simple server application. Unfortunately, time interfered with those plans. However, I hate leaving things under the ‘ole Task List for too long, and this article is a bit overdue. So, here is a quick rundown of using IPC mechanisms under Cygwin. I won’t go into detail because there are much more robust tutorials on Unix based IPC mechanism out there (here, here and my personal favorite here).
This program is pretty simple. It will simple create two shared memory segments, one to store a random integer that will be populated by a parent processed, and one to track the number of child processes. When a child dies, it will subtract from the process tracker. The child processes will poll the shared memory every few seconds and die after 20 attempts. The parent process will reset the value of the shared memory integer after a few seconds. The time delay will overlap to demonstrate the child processes are indeed sharing the memory with the parent processes and each other. This builds on the fork example mentioned above. In this example, I wrote it for specific use under Cygwin, using Cygwins IPC service for Windows. The IPC mechanism is Cygwin can get a little confusing since there are two different ones to use. If you are installing a newer Cygwin release, be sure to include this Windows service. I don’t even know if the IPCDaemon executables are options with Cygwin anymore. Anyway here is the example:
/* * A very simple server using Shared Memory example to communicate between processes. * * The parent will assign the shared memory segment to a random integer, and the child process will * display what it sees. */ //needed for the Shared Memory Functionality //#include <sys/ipc.h> #include <sys/shm.h> //console based IO library #include <iostream> //For generating our keys #include <cstdlib> //needed for the rand function #include <ctime> //needed to work with time for seeding using namespace std; //These are our function declarations void *get_shared_memory_segment(const int &, const char *); //getting shared memory segments int main(int argc, char *argv[]) { //constants for shared memory sizes const int SHM_INT_SIZE = sizeof(int); const int MAX_CHILDREN = 7; //Message Count int *shared_int, *child_count, pid; //We do not want any geeky stuff happening with the child processes later on, so set this up so that //the parent does not need to wait for the child to terminate signal(SIGCLD, SIG_IGN); //seed the random number generator srand(time(0)); //Be verbose, let the console know how large the shared memory segment is set to cout << "Size of Shared Memory Segment for ints: " << SHM_INT_SIZE << endl; //get our shared memory segments shared_int = (int *)get_shared_memory_segment(SHM_INT_SIZE, argv[0]); child_count = (int *)get_shared_memory_segment(SHM_INT_SIZE, argv[0]); if ((!shared_int) || (!child_count)) { cerr << "Error allocating shared memory!" << endl; shared_int = NULL; child_count = NULL; exit(-1); } //initialize our counts to 0 *shared_int = 0; *child_count = 0; //Repeat indefinitly while (1) { if (*child_count < MAX_CHILDREN) { *child_count = *child_count + 1; cout << "--------------------------------" << endl; cout << "Number of Children after fork: " << *child_count << endl; cout << "--------------------------------" << endl; pid = fork(); if (pid < 0) { cerr << "Error on fork!" << endl; shared_int = NULL; child_count = NULL; exit(-1); } } else { cout << "--------------------------------" << endl; cout << "Max children reached. I am not spawning anymore." << endl; cout << "--------------------------------" << endl; } if (pid == 0) { //Inside of child process for (int x = 0; x < 20; x++) { cout << "I am a child " << getpid() << " and I see: " << *shared_int << endl; sleep(3); } *child_count = *child_count - 1; cout << "--------------------------------" << endl; cout << "I am dieing... Number of Childred: " << *child_count << endl; cout << "--------------------------------" << endl; //Exit child process exit(0); } else { //Inside of parent process *shared_int = rand(); cout << "I am the parent " << getpid() << " and I just set the shared memory segment to: " << *shared_int << endl; sleep(5); } } return 0; /* we never get here due to CTRL-C the parent */ } /////////////////////////////////////////////////////////////////////////////////////// //This will allocate the Shared Memory Segment and return a pointer to that segment void *get_shared_memory_segment(const int &size, const char *filename) { //Variables for our Shared Memory Segment key_t key; int shmid; int err = 0; //This is our local pointer to the shared memory segment void *temp_shm_pointer; //Create our shared memory key for client connections if ((key = ftok(filename, 1 + (rand() % 255) )) == -1) //error("Failed to FTOK"); err = 1; //Connect to the shared memory segment and get the shared memory ID if ((shmid = shmget(key, size, IPC_CREAT | 0600)) == -1) //error("shmget attempt failed"); err = 1; // point the clients to the segment temp_shm_pointer = (void *)shmat(shmid, 0, 0); if (temp_shm_pointer == (void *)(-1)) //error("shmat failure"); err = 1; //Return the pointer if (!err) return temp_shm_pointer; else return 0; }
If you’ve never seen an IPC call, let me explain what is going on here. In this program, we are using an IPC type called Shared Memory. Shared Memory is just that, memory that different programs can share to exchange data. There are other types of IPC’s, which are explained in the IPC tutorials listed above. While this is not really explained in the tutorials, the ftok (file to key) function can use any file that the process can access. In this example, I use the programs actual filename (whatever.exe) rather than some arbitrary filename as indicated in Beejs’s tutorial. I am also using random to help reduce the chances of using the same key. The rest should become clear after reading the tutorials. I will build on this a little more when I have a chance.
My last article showed how to set up BIRT scheduled tasks without any programming. In this article I will demonstrate the same thing, however the report launching will be done from within a Java program. This demonstrates how to use the BIRT API’s to open, launch a report, and save to a specified location. The output location has been changed to C:\Temp instead of the working directory. Information about using the BIRT API’s was obtained from the BIRT Integration Tutorial. The Source Code is below:
public static void main(String[] args) { //Variables used to control BIRT Engine instance EngineConfig conf = null; ReportEngine eng = null; IReportRunnable design = null; IRunAndRenderTask task = null; HTMLRenderContext renderContext = null; HashMap contextMap = null; HTMLRenderOption options = null; //Now, setup the BIRT engine configuration. The Engine Home is hardcoded //here, this is probably better set in an environment variable or in //a configuration file. No other options need to be set conf = new EngineConfig(); conf.setEngineHome("C:/birt_runtime/birt-runtime-2_1_0/ReportEngine"); //Create new Report engine based off of the configuration eng = new ReportEngine( conf ); //With our new engine, lets try to open the report design try { design = eng.openReportDesign("C:/birt_runtime/birt-runtime-2_1_0/ReportEngine/samples/hello_world.rptdesign"); } catch (Exception e) { System.err.println("An error occured during the opening of the report file!"); e.printStackTrace(); System.exit(-1); } //With the file open, create the Run and Render task to run the report task = eng.createRunAndRenderTask(design); //Set Render context to handle url and image locataions, and apply to the //task renderContext = new HTMLRenderContext(); renderContext.setImageDirectory("image"); contextMap = new HashMap(); contextMap.put( EngineConstants.APPCONTEXT_HTML_RENDER_CONTEXT, renderContext ); task.setAppContext( contextMap );
//This will set the output file location, the format to rener to, and //apply to the task options = new HTMLRenderOption(); options.setOutputFileName("c:/temp/output.html"); options.setOutputFormat("html"); task.setRenderOption(options); //Cross our fingers and hope everything is set try { task.run(); } catch (Exception e) { System.err.println("An error occured while running the report!"); e.printStackTrace(); System.exit(-1); } //Yeah, we finished. Now destroy the engine and let the garbage collector //do its thing System.out.println("All went well. Closing program!"); eng.destroy(); } }
The next step after this would be to parameterize the input file, output file, and output format. Then this program could be used for any report, not just this specific report. I intend to build on this example a little more, and possibly use the parameters to specify a configuration file that will be built in XML and use Apache Xerces (or, in Java 1.5, the XML components that are now included with the standard Java libraries). However, since the Xerces components are already included with the BIRT Runtime libraries, I am leaning more towards using those.
Previously I had written about a way to schedule reports to run with BIRT using Apache Tomcat, wget, and a scheduling service. To me, this is a cumbersome and inelegant solution to a very simple problem. However, one of the great things about BIRTS architecture is that there are a number of different solutions to any given problem. In this article, I will show a simple way to schedule BIRT reports to run automatically that requires no programming and does not require Tomcat to run. This is a great solution for those who, like me, do not like the idea of loading unnecessary services where they are not required.
There are only two requirements for this solution. First and foremost, be sure to have Java on the machine that will run the reports. I have come to prefer Sun Java to other Java or Java-like solutions, such as the GNU Java interpreter. I had previously written about many compatibility issues running Eclipse and other Java centric programs using interpreters other than Suns. The second requirement is that you have the BIRT Runtime libraries, available from the BIRT Download page. For this example I am using BIRT 2.1 runtime, which has been extracted to C:\birt_runtime. I will use the Hello_World.rptdesign file that is included with the BIRT Runtime package, located under C:\birt_runtime\birt-runtime-2_1_0\ReportEngine\samples and output to HTML under the same directory. I will use the Windows Task scheduler to schedule this report to run each night.
First, I am going to create a batch file called runReport.bat. The file will be simple and only have the following lines: Set BIRT_HOME=C:\birt_runtime\birt-runtime-2_1_0\ C:\birt_runtime\birt-runtime-2_1_0\ReportEngine\genReport.bat -runrender -output "c:\birt_runtime\birt-runtime-2_1_0\ReportEngine\sameples\output.html" -format html “C:\birt_runtime\birt-runtime-2_1_0\ReportEngine\samples\Hello_World.rptDesign”
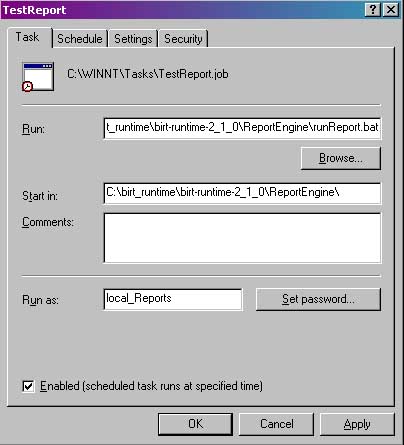
To Schedule this file to run, I go under Control Panel, Scheduled Task, and create a new Scheduled Task. I set the command to run as C:\birt_runtime\birt-runtime-2_1_0\ReportEngine\runReport.bat. I set up the appropriate time, and set the directory to start in as C:\birt_runtime\birt-runtime-2_1_0\ReportEngine\. I also set this to run as a dedicated report user. Figure 1 illustrates the values I used under Scheduler.
Figure 1. Values used to run BIRT report. Now, I can schedule BIRT Reports to run without needing Apache. This cuts down on system overhead. There are a few caveats to take into consideration. If your BIRT report hits a database, the appropriate drivers will need to be included in the ReportEngine\plugins folders. For example, if the report uses JDBC to connect, the JDBC drivers will need to be installed under the ReportEngine\plugins\ org.eclipse.birt.report.data.oda.jdbc_<version> folder. Also, you will need to copy the iText.jar file as indicated in the BIRT Runtime installation instructions to the appropriate plugins directory.
From this exercise I learned a few interesting things. I was unaware that Java classes could be invoked from the command line. For example, if I set a environment variable called BIRT Class Path like so: SET BIRTCLASSPATH=%BIRT_HOME%\ReportEngine\lib\commons-cli-1.0.jar;%BIRT_HOME%\ReportEngine\lib\commons-codec-1.3.jar;%BIRT_HOME%\ReportEngine\lib\com.ibm.icu_3.4.4.1.jar;%BIRT_HOME%\ReportEngine\lib\coreapi.jar;%BIRT_HOME%\ReportEngine\lib\dteapi.jar;%BIRT_HOME%\ReportEngine\lib\engineapi.jar;%BIRT_HOME%\ReportEngine\lib\js.jar;%BIRT_HOME%\ReportEngine\lib\modelapi.jar;%BIRT_HOME%\ReportEngine\flute.jar;%BIRT_HOME%\ReportEngine\lib\sac.jar; I can run the following command from the DOS prompt and get the parameters that the ReportEngine class is expecting:
java -cp "%BIRTCLASSPATH%" org.eclipse.birt.report.engine.api.ReportRunner org.eclipse.birt.report.engine.impl.ReportRunner --mode/-m [ run | render | runrender] the default is runrender for runrender mode: we should add it in the end<design file> --format/-f [ HTML | PDF ] --output/-o <target file> --htmlType/-t < HTML | ReportletNoCSS > --locale /-l<locale> --parameter/-p <parameterName=parameterValue> --file/-F <parameter file> --encoding/-e <target encoding> Locale: default is english parameters in command line will overide parameters in parameter file parameter name can't include characters such as ' ', '=', ':' For RUN mode: we should add it in the end<design file> --output/-o <target file> --locale /-l<locale> --parameter/-p <parameterName=parameterValue> --file/-F <parameter file> Locale: default is english parameters in command line will overide parameters in parameter file parameter name can't include characters such as ' ', '=', ':' For RENDER mode: we should add it in the end<design file> --output/-o <target file> \t --page/-p <pageNumber> --locale /-l<locale> Locale: default is English For me, this is a major break from the paradigm of compile and run software in other languages.
Next article, I will show how the same thing can be accomplish programmatically using the BIRT API’s to run the report.
I am a computer programmer by trade, and a fitness enthusiast.
I have been writing about programming for several years, and am the author of "Practical Data Analysis and Reporting with BIRT" and "BIRT 2.6: Data Analysis and Reporting". I am a full time consultant specializing in Business Intelligence, enterprise search, and eCommerce.
I do Gracie Jiu-Jitsu, P90X, and Insanity. I am a BeachBody coach and reseller for P90X, Insanity, and Shakeology.