I first heard of BIRT at the Actuate Users conference in August of 2004. Paul Clenahan, one of Actuate’s VPs, described how Actuate is embracing the Open Source development model. He was of course talking about BIRT. Interested, I approached him afterward and we discussed some aspects of how BIRT could benefit the Sguil project. At the time, Actuate was offering BIRT as a module for Eclipse in very early development. I signed up for the pre-release versions and evaluated over the course of the year. At the 2005 Actuate Conference, they announced that they had released a standalone version, which did the full installation of Eclipse with the BIRT workspace preconfigured and ready to roll. More information on both the Eclipse plug-in and standalone versions of BIRT can be found at http://www.actuate.com/birt and http://www.eclipse.org/birt.
I prefer the approach of separating the reporting system from Sguil for two key reasons: 1) singularity of purpose, and 2) additional flexibility. To my first point, separating out the reporting system coincides with the Unix philosophy that a tool should do one thing and do it well. By separating the reporting functionality from the IDS system, you avoid adding an additional layer of complexity. Sguil’s main focus should be as a console for network security analysts, and I feel that reporting is outside of that scope. Second, you gain much more flexibility with BIRT as a reporting platform; you can develop as many reports as you need with customized look, feel, and report criteria with very little development. With Sguil’s built-in reports, you are limited to what the project developers have time to provide. Report modifications require someone to modify the TCL source code. BIRT has the potential to take NSM operations to the next level in terms of reporting capabilities by tailoring the data to meet decision-making managers’ needs.
Lets take a look at BIRT. There are two type of BIRT packages: standalone packages and Eclipse plug-ins. In the standalone category, there are type types of installation packages, BIRT Report Designer (BRD) and BIRT Report Designer Professional. I will only take a look at BIRT Report Designer in this article. (Perhaps Professional will be a topic for a future article.) The install packages are roughly 100 MB for BRD Pro and 75 MB apiece BRD. The installers for the Standalone version seem to be in the Windows® variety only, while the Eclipse plug-ins are platform-independent Java files.
Installation of BRD is fairly simple: just click on the executable and go. This brings you into the familiar Windows® Install Shield program. The first few screens are just a title screen and the EULA. The next screen asks if you want to do a typical install or a custom install. I always choose custom, and I always keep the install directory default. The custom options only give you the BIRT core so there is not a lot of variety or options to set. It seems to me that they could easily remove the typical/custom choice.
You will also need to get JDBC drivers for MySQL to write reports for Sguil. I download the JDBC Drivers from http://dev.mysql.com/downloads/connector/j/3.0.html. I used the 3.0 drivers because the 3.1 drivers gave me some issues. After downloading, extract the files to C:\MySQL.
After installation, I start BIRT from the appropriate Start Menu location, located under Programs, and Actuate Birt 1.0.1. This seems to be an all-inclusive install package since the environment looks exactly like Eclipse with the BIRT perspective open.
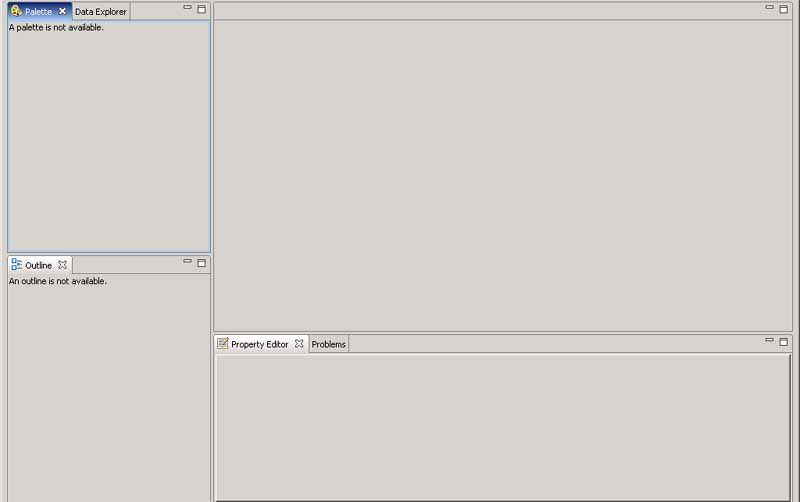
On the left hand side is our Palette, Outline, and Data Explorer. Since this is a tabbed interface, you can drag tabs into any floating palette that you choose. For this example I will keep things as is, but I usually like to drag my Data Explorer with my outline to keep my report design elements separate from my design components, but that is a personal preference. On the bottom of the page is the Properties and Property Editor. The Property Editor is a custom layout for whatever component you are working with, while the Properties tab will show you a tree view of all properties that belong to that component.
In this example, I want to create a basic report with BIRT using the Sguil database. This is a simple report Summary page that will display a count of all the incidents in the Sguil database grouped by category. I will break out the report into two columns, with the left side displaying the Category title, and the right displaying the count of events to date.
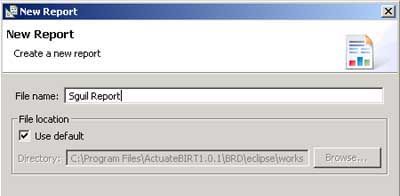
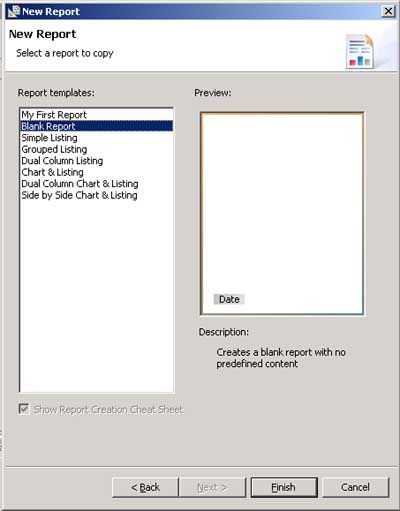
First, go up to the “File” and “New Report”. On the report title page, I just entered “Sguil Report”. The next screen gives you report templates to use. Since this will be a very simple report, I chose blank report and clicked Finish.
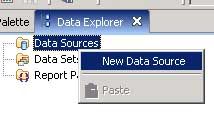
Next thing I do is go over to the Data Explorer tab. I can see that I do not have a data source, without which I cannot pull any data for my report. So I need to define a new Data Source. I right mouse click on Data Source and choose “New Data Source”.
I will need to add the MySQL JDBC drivers in order to continue. Next, I choose Manage Drivers. Then I click on Add and point to the directories where the JAR files reside under the C:\MySQL directory.
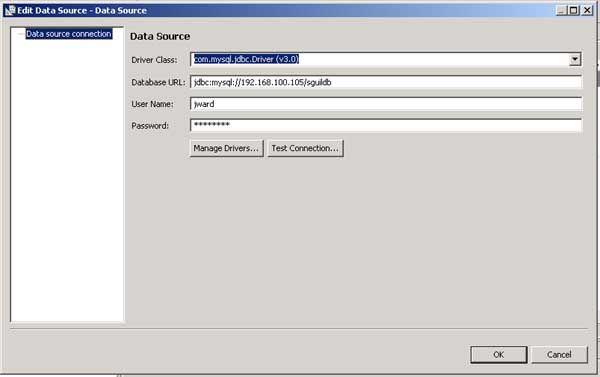
Back on the Add Datasource screen, I add the information like in the picture below. Note the Database URL syntax. In this case I used jdbc:mysql://192.168.100.105/sguildb, where 192.168.100.105 is the IP address of my MySQL database and sguildb is the name of the database for Sguil.
Returning to the Data Explorer, I right mouse click on the newly created Data Source and choose rename, so I can rename the component SguilDataSource. Now I need to create a Data Set (known as a Recordset in other environments). I right mouse click on Data Sets. The first page in the properties dialog is the SQL screen. I enter the following SQL statement:
SELECT
status,
count(status)
FROM
event
GROUP BY
status
To speed up future reports, I create the following index for the Sguil database:
create index
evnt_status
on
event(status);
With my Data Source and Data Set created, I am ready to create my report body. First, I move back to my Palette, which is located on the right hand side of the workspace. I select a “Table” object from the drop down list and drag it over to my report body.
When the Setup Table dialog appears, I select 2 Columns and 1 row. Even so, what I end up with is 3 actual rows: one header, one detail, and one footer.
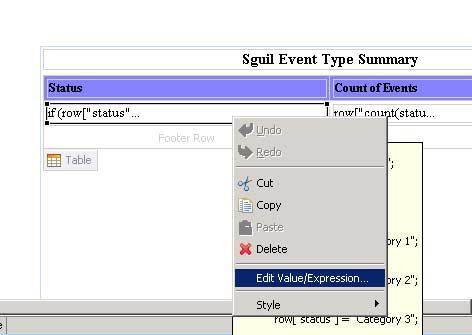
I need to add data to the table. I go back to the DataExplorer and expand the Data Set branch. I drag “Status” over to the first column, and “count(status)” to the second column. Now if I preview my report, I will see that status is going to display the numbers of the Status ID’s, not the status it actually stands for. So I need to do a replace of these values. To correct this, I need to add a bit of code to interpret what these values mean, and I will do so in the Value Expression for the status cell. I do this by double clicking on the status cell to open up the Expression Builder. Alternatively you can right mouse click on the status cell and choose “Edit Value/Expression” as pictured below.
To replace the values I put in the following code:
if (row["status"] == "0")
row["status"] = "Active";
if (row["status"] == "1")
row["status"] = "N/A";
if (row["status"] == "11")
row["status"] = "Category 1";
if (row["status"] == "12")
row["status"] = "Category 2";
if (row["status"] == "13")
row["status"] = "Category 3";
if (row["status"] == "14")
row["status"] = "Category 4";
if (row["status"] == "15")
row["status"] = "Category 5";
if (row["status"] == "16")
row["status"] = "Category 6";
For some odd reason, using a switch statement did not work here. Now, I click OK and go back to the report designer. I change the headers for each column by clicking on the header cells and entering the desired text in the “Text” property. My table is shown below.
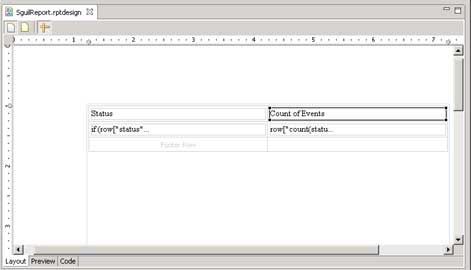
To me this report is very plain, so lets add a few more elements. I need to add a report title to this page, and I want to change the color of the header row. To add the report title is easy. I go over to the component palette, and drag a label over. I change the text in it to “Sguil Report Type Summary”. Using the standard text controls at the bottom, it’s easy to bold the title, make it large, and center it. Changing the color of the header row is accomplished in the Outline tab, by selecting the table, header, and row. Then I go into the Property window to set the background color to blue, and set the font weight to bold.
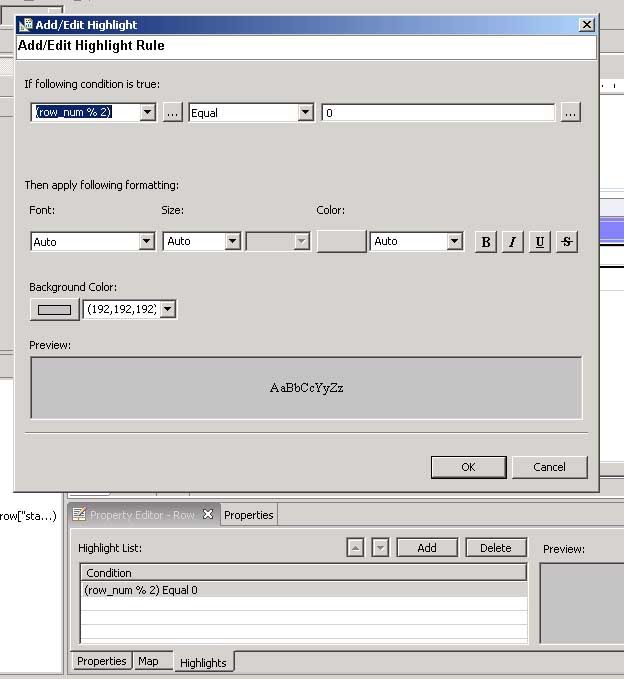
The last thing is to have the colors alternate in the detail rows to make the report easier to read. First, I create a parameter to store the row number. The next step is to go over to the data explorer, right mouse click on Report Parameters and choose New Report Parameter.
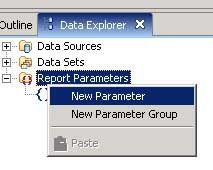
I enter in the name of the parameter and check the boxes for Allow Null Values, Hidden, and Do Not Echo Input. Next I set the type to float, and change the format to fixed. Then it’s back to the report outline, where I right mouse click on the Sguil Report parent object and select Edit Code.
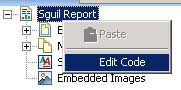
It’s time to change the function to Initialize and set the row number parameter to its initializing value.
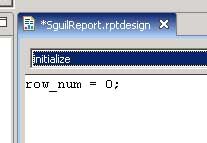
Now I go back to the Outline, select the table element, right mouse click and choose Edit Code. At the OnRow function, the parameter is incremented by 1 using the ++ operator.
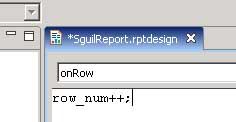
Now, here comes the magic: in the Outline, I select Row under the Table object and go into the Property Editor for the Row. Then I select the Highlights tab and click on the Add button. Input the formula as shown below, I select a background color.
Below is a screenshot of the final product.
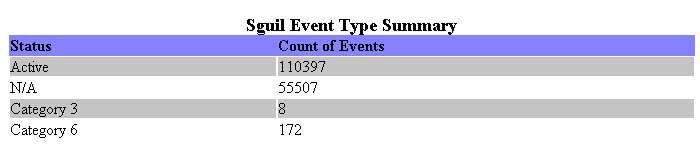
Now the report is complete. Although I did not cover using parameters, we could easily modify this report to include parameters for a specific date range, or only a certain set of categories. Using BRD, the report can be outputted using the Preview as HTML or Preview as PDF options under the file menu. If you would like to automate the report process, you can publish the final report design file to an Apache Tomcat server and schedule it to run at regular intervals.
BIRT reporting capabilities can help NSM operations by filling in the deficiencies in Sguil’s reporting capabilities. By being able to provide ad-hoc reports, NSM operations can effectively communicate incidents and policy violations in a manner that will allow stakeholders to make informed decisions about their security policies. I hope NSM operations find this a useful tool for working with their customers.