The first step is to get the additional prerequisite packages for BIRT. I already have the base Eclipse packages needed as outlined in the EclipseZone article. Additionally BIRT 2.0 will require Apache Axis, iText, prototype.js, and the BIRT 2.0 Framework. Apache Axis is the first of the prerequisite packages I retrieved. Fortunately only 6 files are needed for BIRT, so I open the file in WinZip, and sort by file type. I select all the “Executable JAR files” and extract to a temporary directory.
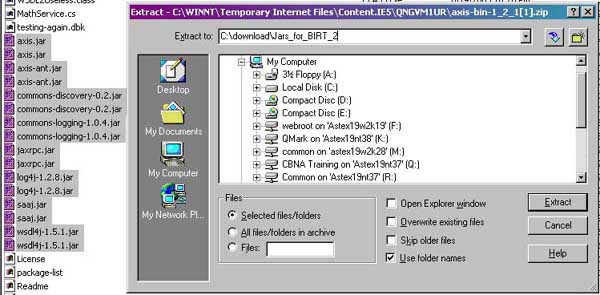
I will only keep the following 6 files:
axis.jar axis-ant.jar commons-discovery-0.2.jar jaxrpc.jar saaj.jar wsdl4j-1.5.1.jar
I extract the ZIP file to C:\Download\Jars_for_BIRT_2\. The 6 files were found under the following directory:
C:\download\Jars_for_BIRT_2\axis-1_2_1\lib
iText. was saved to C:\ Download\Jars_for_BIRT_2\iText
And finally I downloaded prototype.js and saved it to C:\ Download\Jars_for_BIRT_2\.
I downloaded the BIRT 2.0 Framework from here.
Now that I have the components downloaded, I need to remove my original BIRT installation before I begin installing 2.0. The first thing I do is locate my Eclipse folder, and delete all subfolders starting with org.eclipse.birt.
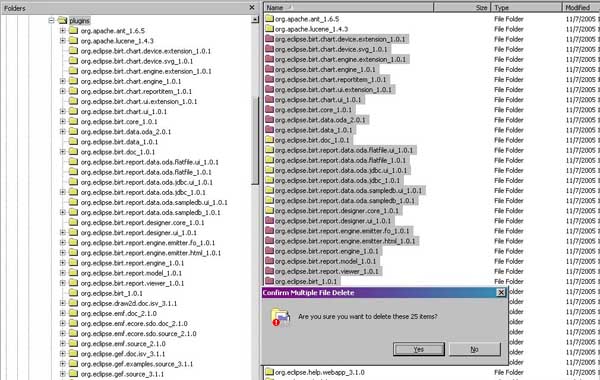
For grins, I also run “eclipse –clean” to clear out any old garbage relating to the old version of BIRT.
I do get an error message warning me about not being able to load my workbench (which was BIRT the last time I ran Eclipse), but it can be ignored. From there I close Eclipse.
Next I open up my Zip file for the BIRT 2.0 Framework and extract to the folder containing Eclipse, with full directory options on.
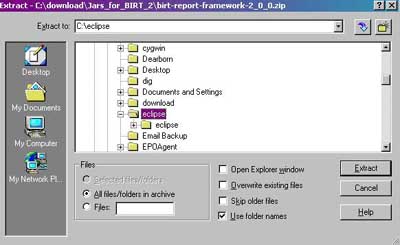
Now that the directory structure is created for BIRT, I copy the 6 files from Apache to the C:\eclipse\eclipse\plugins\org.eclipse.birt.report.viewer_2.0.0\birt\WEB-INF\lib
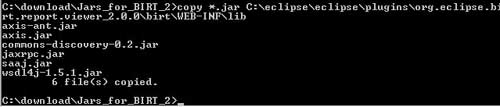
Then I copy iText over
And finally, I copy over prototype.js to the appropriate BIRT directory

Once done, I go into the Eclipse folder, and launch Eclipse with the –clean switch again.

I am stoked that I do not get the workspace error again, and I can open the Employees example I used for the EclipseZone article. The only thing I need to do is to load my JDBC driver for Oracle again. These steps are outlined in the EclipseZone article and in Sguil Incident Reporting using BIRT articles, so I will not repeat them here. (Note: I ran into a bug here while writing this article. If you go into manage drivers, cancel out, then go back into manage drivers, the dialog will not pop up. I did have a BIRT 1 report opened at the time which was expecting the JDBC driver, so no telling if that is the catalyst for this bug. Annoying, but not critical).
Once added, I was successfully able to run the Employee test report under BIRT. I will play around with the new features in 2.0 and report back what I find.

